
What was some of the difficulty you ran into?
I haven’t had to do anything weird but I don’t need anything outside of flatpaks usually.
For most other things a container with more traditional package management works well.
reddit refugee
What was some of the difficulty you ran into?
I haven’t had to do anything weird but I don’t need anything outside of flatpaks usually.
For most other things a container with more traditional package management works well.
Bazzite worked well for me with dual monitors and a 1060. But I can’t speak for 3 monitors and a 4070.
I paid for lifetime in 2012. Worth it.

Hm. Let’s see what I get.
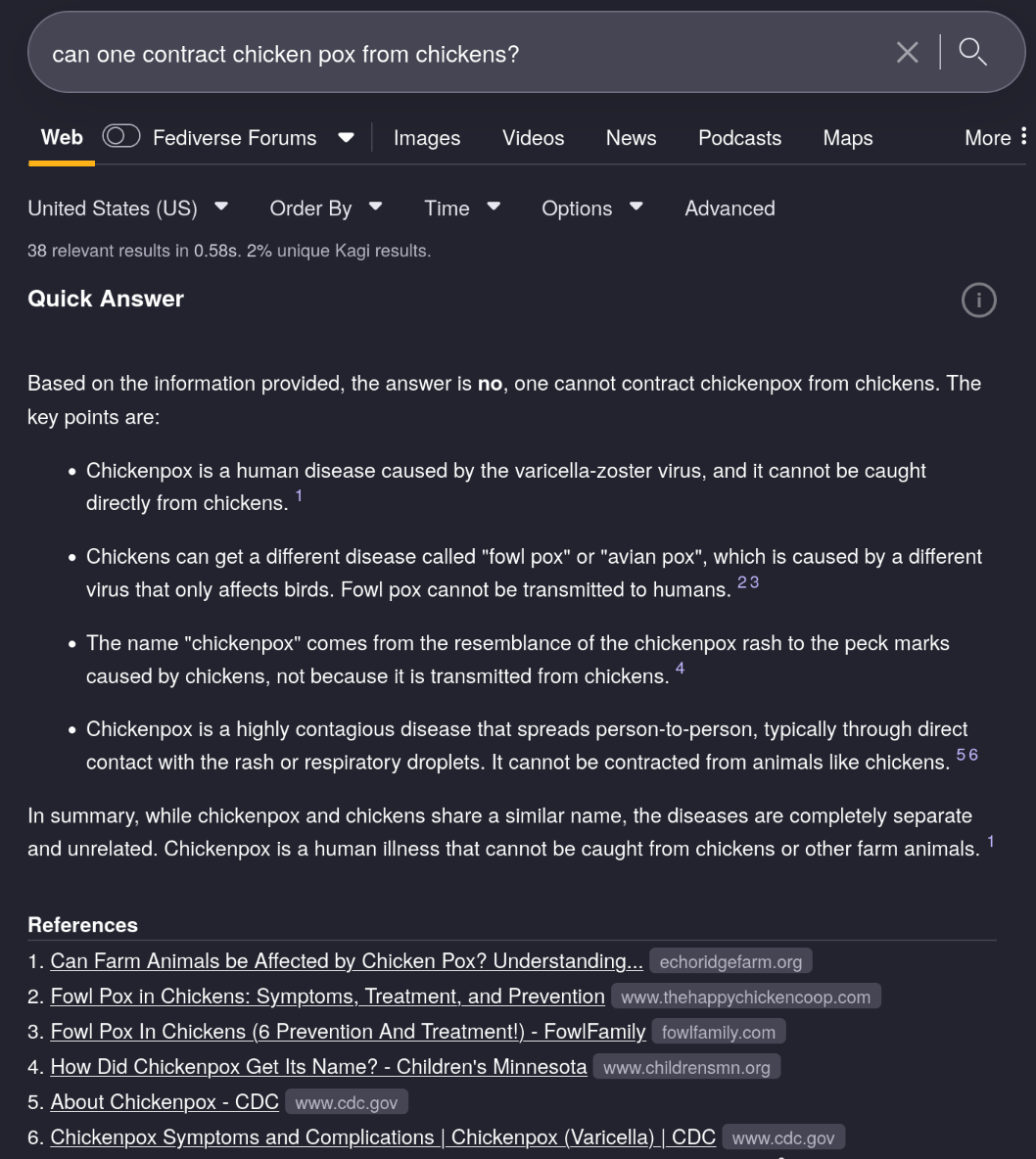
And here’s another one for good measure:
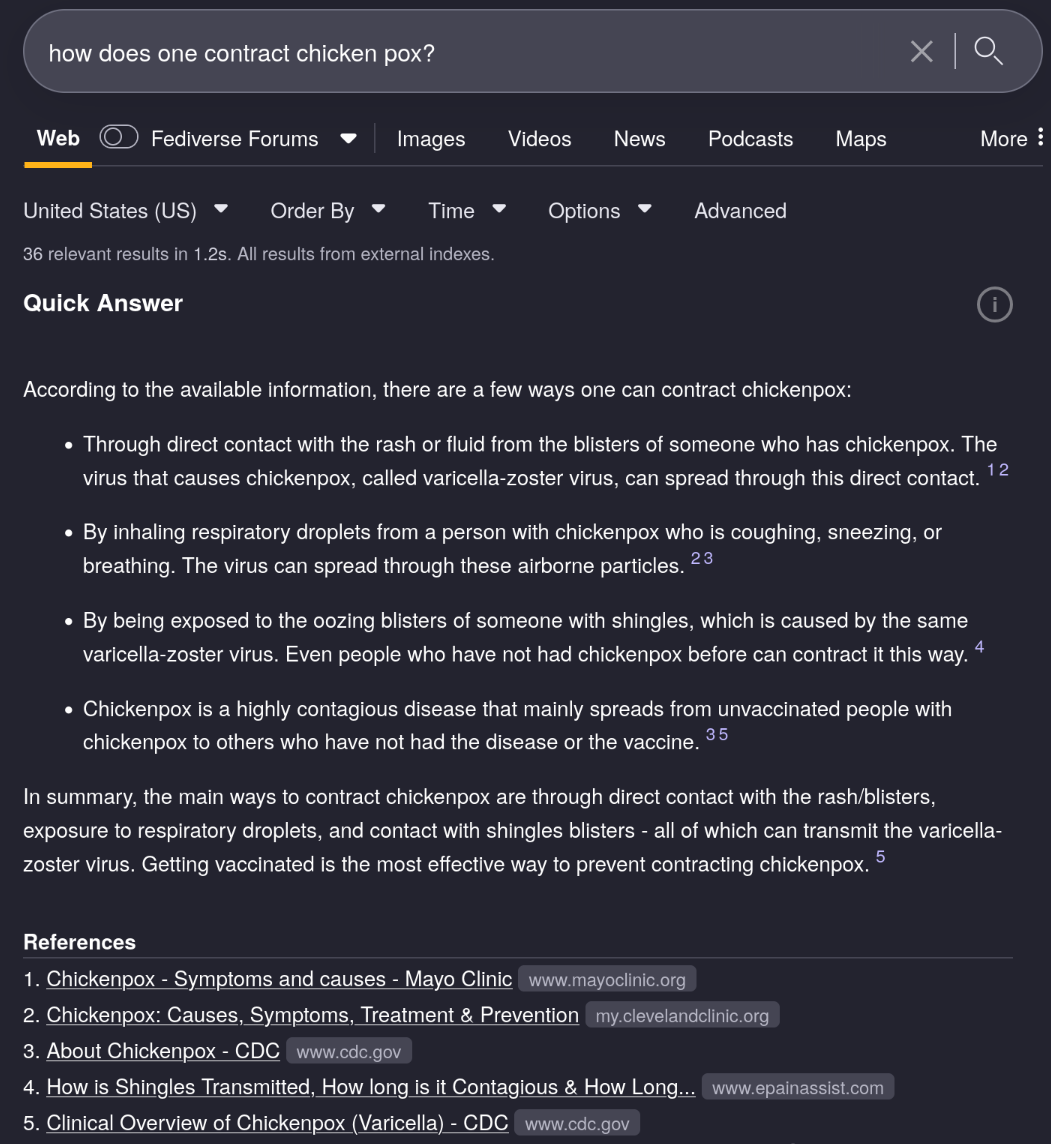

It is, yes. But it’s also legal to make your own.

Bro keep up. They doin’ it again.

What’s your sample size, do you actually talk to many gen z
They aren’t the only ones to have noticed this issue.
If you asked them where they saved a photo on a smartphone…
“Where did you save the file” isn’t typically asked in the context of a smart phone. Maybe on Android more so than iOS.
The problem with your argument is that it is 100% possible to get ChatGPT to produce verbatim extracts of copyrighted works.
What method still works? I’d like to try it.
I have access to ChatGPT 4, and the latest Anthropic model.
Edit: hm… no answers but downvotes. I wonder why that is.
Guess if they pass we’ll see how they stand up to the 1st.
Ahh my mistake.
Might be time to financially contribute to IA.
It’s mentioned in the OP but it’s this:
https://wiki.archiveteam.org/index.php/ArchiveTeam_Warrior
Basically, distributed collection.
We get it, y’all hate LLMs and the companies who make them.
This comparison is disingenuous and I have to think you’re smart enough to know that, making this disinformation.
If/when an LLM like ChatGPT spits out a full copy of training text, that’s considered a bug and is remediated fairly quickly. It’s not a feature.
What IA was doing was sharing the full text as a feature.
As far as I know, there are some court cases pending regarding determining if companies like Open AI are guilty of copyright infringement but I haven’t seen any convictions yet (happy to be corrected here).
All that said, I love IA and have a Warrior container scheduled to run nightly to help contribute.
Wait till this crowd hears about smoke detectors.
That’s a little different than what I mean.
I mean to run a single bot from a script which interacts a normal human amount during normal human times within a configurable time zone which is acting as a real person just to poison their dataset.
Also send this junk to Reddit comments to poison that data too because fuck Spez?
Women are the most vulnerable in the world.
Yeah that was fun times.
Luckily, thanks to using docker, it was easy enough to “pin” a working version in the compose file while I figured out what just broke.
For everyone’s reference, here’s my fstab to give you an idea of what works with linuxserver.io’s qbittorrent
## Media disks setup for mergerfs and snapraid
# Map cache to 1TB SSD
/dev/disk/by-id/ata-Samsung_SSD_860_EVO_1TB_S3Z8NB0K820469N-part1 /mnt/ssd1 xfs defaults 0 0
# Map storage and parity. All spinning disks.
/dev/disk/by-id/ata-WDC_WD100EZAZ-11TDBA0_JEK39X4N-part1 /mnt/par1 xfs defaults 0 0
/dev/disk/by-id/ata-WDC_WD100EZAZ-11TDBA0_JEK3TY5N-part1 /mnt/disk01 xfs defaults 0 0
/dev/disk/by-id/ata-WDC_WD100EZAZ-11TDBA0_JEK4806N-part1 /mnt/disk02 xfs defaults 0 0
/dev/disk/by-id/ata-WDC_WD100EZAZ-11TDBA0_JEK4H0RN-part1 /mnt/disk03 xfs defaults 0 0
/dev/disk/by-id/ata-WDC_WD30EFRX-68EUZN0_WD-WCC4N4XFT0TS-part1 /mnt/disk04 xfs defaults 0 0
/dev/disk/by-id/ata-WDC_WD30EFRX-68EUZN0_WD-WCC4N4XFT1YS-part1 /mnt/disk05 xfs defaults 0 0
/dev/disk/by-id/ata-WDC_WD30EFRX-68EUZN0_WD-WCC4N4XFT3EK-part1 /mnt/disk06 xfs defaults 0 0
/dev/disk/by-id/ata-WDC_WD30EFRX-68EUZN0_WD-WCC4N6CKJJ6P-part1 /mnt/disk07 xfs defaults 0 0
# Setup mergerfs backing pool
/mnt/disk* /mnt/stor fuse.mergerfs defaults,nonempty,allow_other,use_ino,inodecalc=path-hash,cache.files=off,moveonenospc=true,dropcacheonclose=true,link_cow=true,minfreespace=1000G,category.create=pfrd,fsname=mergerfs 0 0
# Setup mgergerfs caching pool
/mnt/ssd1:/mnt/disk* /mnt/cstor fuse.mergerfs defaults,nonempty,allow_other,use_ino,inodecalc=path-hash,cache.files=partial,moveonenospc=ff,dropcacheonclose=true,minfreespace=10G,category.create=ff,fsname=cachemergerfs 0 0




If I get back into it, I’ll probably try out Bigscreen. I haven’t dug deep enough into it to know if it requires an account but I wouldn’t expect this one to require it.