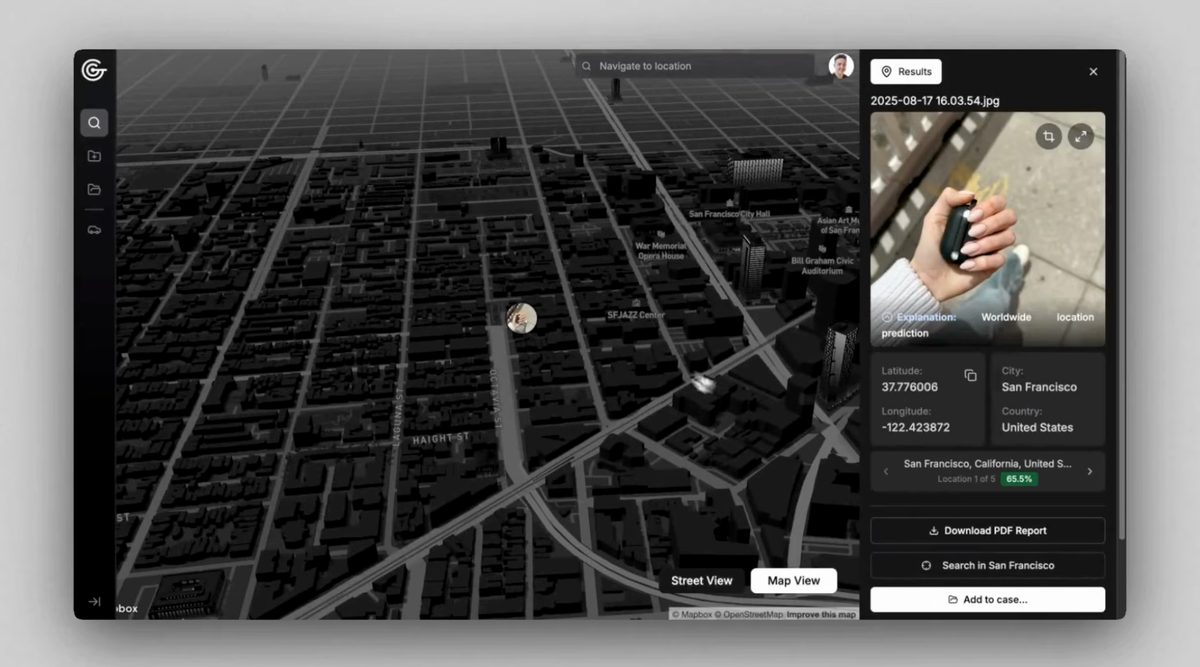
404 Media has obtained a cache of internal police emails showing at least two agencies have bought access to GeoSpy, an AI tool that analyzes architecture, soil, and other features to near instantly geolocate photos.
When researchers peeked into which areas of the image were being used, it showed that the tiny camera watermark from the Google Streetview car was being used by the model a lot.
That is, the recognition system had learned all the routes every Google Street view car had taken, and was using that in its recognition process.
Not all images have this watermark though, so in the cases the watermark didn’t exist it then resorts to more traditional geoguessr tactics.
This system wouldn’t a simple ‘put image into a multimodal LLM and get an answer’ like using ChatGPT.
It’d do things like image segmentation and classification, so all of the parts of the image are labeled and then specialized networks would take the output and do further processing. For example, if the segmentation process discovered a plant and a rock then those images would be sent to networks trained on plant or rock identification and their output would be inserted in to the image’s metadata.
Once they’ve identified all of the elements of the photos there are other tools that don’t rely on AI which can do things like take 3D maps of an suspected area and take virtual pictures from every angle until the image of the horizon matches the image in the pictures.
If you watch videos from Ukraine, you’ll see that the horizon line is always obscured or even blurred out because it’s possible to make really accurate predictions if you can both see a horizon in an image and have up to date 3D scans of an area.
The research paper that you’re talking about was focused on trying to learn how AI generate output from any given input. We understand the process that results in a trained model but we don’t really know how their internal representational space operates.
In that research they discovered, as you have said, that the model learned to identify real places due to watermarks (or artifacts of watermark removal) and not through any information in the actual image. That’s certainly a problem with training AIs, but there are validation steps (based on that research and research like it) which mitigate these problems.


Eh, kind of both.
When researchers peeked into which areas of the image were being used, it showed that the tiny camera watermark from the Google Streetview car was being used by the model a lot.
That is, the recognition system had learned all the routes every Google Street view car had taken, and was using that in its recognition process.
Not all images have this watermark though, so in the cases the watermark didn’t exist it then resorts to more traditional geoguessr tactics.
This system wouldn’t a simple ‘put image into a multimodal LLM and get an answer’ like using ChatGPT.
It’d do things like image segmentation and classification, so all of the parts of the image are labeled and then specialized networks would take the output and do further processing. For example, if the segmentation process discovered a plant and a rock then those images would be sent to networks trained on plant or rock identification and their output would be inserted in to the image’s metadata.
Once they’ve identified all of the elements of the photos there are other tools that don’t rely on AI which can do things like take 3D maps of an suspected area and take virtual pictures from every angle until the image of the horizon matches the image in the pictures.
If you watch videos from Ukraine, you’ll see that the horizon line is always obscured or even blurred out because it’s possible to make really accurate predictions if you can both see a horizon in an image and have up to date 3D scans of an area.
The research paper that you’re talking about was focused on trying to learn how AI generate output from any given input. We understand the process that results in a trained model but we don’t really know how their internal representational space operates.
In that research they discovered, as you have said, that the model learned to identify real places due to watermarks (or artifacts of watermark removal) and not through any information in the actual image. That’s certainly a problem with training AIs, but there are validation steps (based on that research and research like it) which mitigate these problems.