
18·
1 day agoIt’s right-wing trolling that it’s specifically non-binary. It’s just iconography they use throughout Firefox, when displaying error messages or the like.
It’s right-wing trolling that it’s specifically non-binary. It’s just iconography they use throughout Firefox, when displaying error messages or the like.

Mozilla didn’t bring it up. The story is made up by right-wing trolls.
This story is made up by right-wing trolls.
The dino represents Mozilla, not Firefox itself. And yes, for a while, Mozilla didn’t have the dino in its official branding, but it’s now back in there. The flag is a dino head. As per usual, significantly more drama was made about them “removing” the dino than it was worth.
They’re not talking about language with the male-as-default, but rather for example this:

The depiction with less discerning features is what we assume to be male. If you want to express female, you have to add a dress or long hair or curves etc…
There’s actual scientific research on this bias existing, although I don’t know in what way this extends to animal depictions.
There’s also analog computers: https://en.wikipedia.org/wiki/Analog_computer
Alas, they got largely displaced by digital computers…

These days, you also likely get faster loading times when you self-host the font, because it can be sent through the same HTTPS connection and because caching doesn’t work anymore like it used to many years ago (cached files aren’t shared anymore between websites).
Ah, I meant that as in the individual hair have less circumference and therefore are easier to cut through.
Personally, I find it much easier down under, because the hair is a lot thinner…

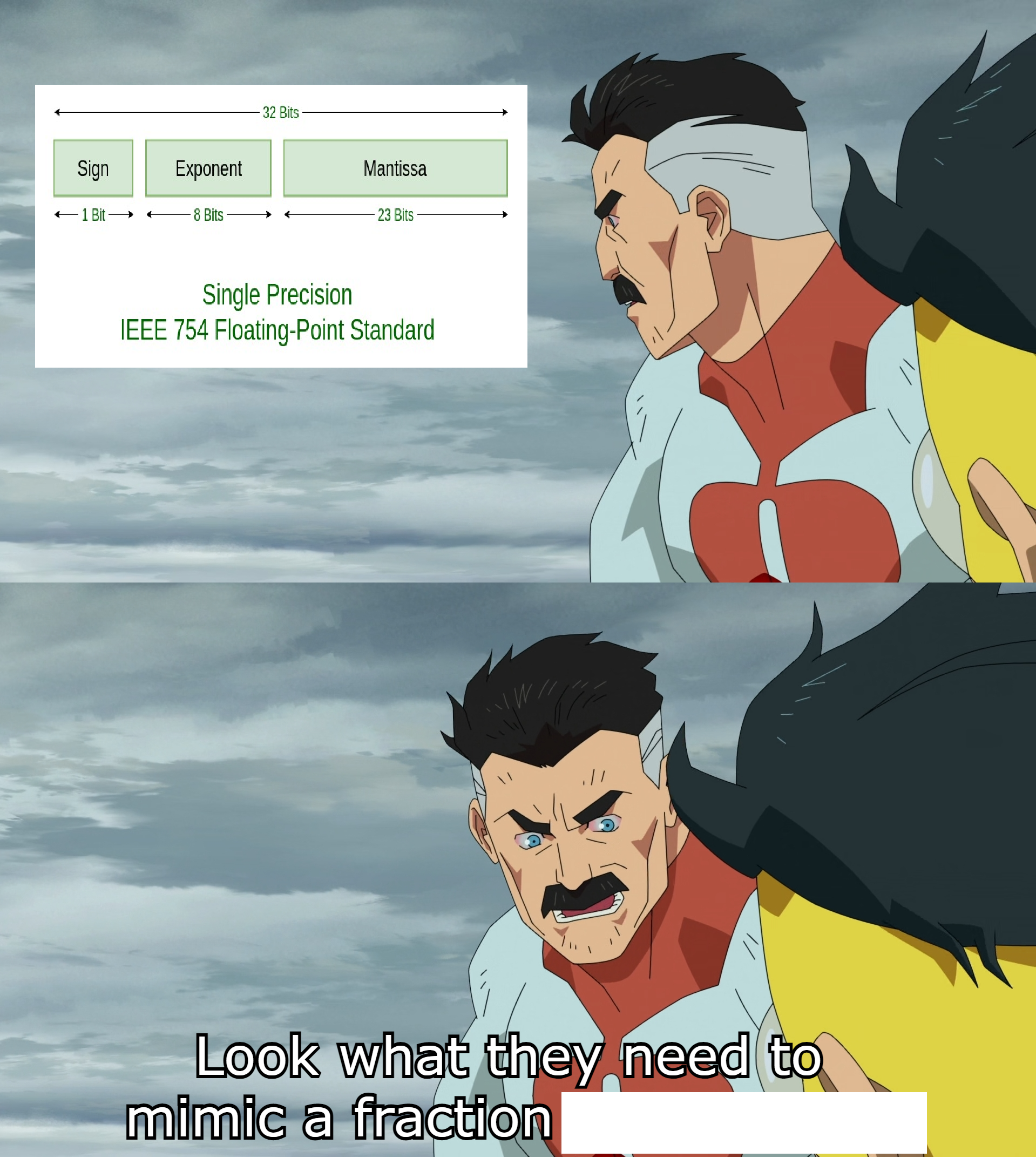
Okay, but just to be clear, the problem is not that it can’t do a timer. The problem is that it claims to be able to and even produces a result which looks plausible. It means, you cannot trust it to do anything that you can’t easily verify. If they could fix that overconfidence in a year, it would be much better.
My first thought was bugs and berries looking similar to a marble, but moving water makes a lot of sense. There’s for example also cat fountains you can buy, because some cats won’t drink the still water in a bowl.
Can certainly also see why it got named that… 🙃
“As always.” is an old favorite of mine. They’ll assume things are neither particularly good nor bad, when what you mean is that you always feel bad.

I’ve been wondering, if you could combine LLMs with a logic programming language like Prolog. The latter is actually able to reason through things, you “just” have to express them in Prolog facts and rules.
Well, from doing a quick online search, I’m most certainly not the first person to think of this, which does not surprise me at all…

Hmm, is the last staff thing just the death message from Sif Muna? I seriously don’t play often enough with Sif Muna, because Heplhjdtfhxhdh always seems so good… 🥴
Yeah, I’m aware. Just sharing that the article author kind of wrote an even worse sounding sentence, and I can’t help but feel that !theyknew@lemmy.sdf.org.
Yeah, in particular, anything close to 100 million users presumes that non-gamedevs will use this. For anything beyond simple variations of existing games, like e.g. “Skyrim with spears”, you need to have an actual understanding of game design. It is not enough to have cool ideas.
So, I really don’t see many non-gamedevs using this. Especially when they can pay less to play a properly designed game.
The subtitle, from where the screenshot is from, is:
Scientists find ways to sex chicks before they hatch
🥴
That is precisely what it is, yeah. I found it funny to post it here without context, because it just seems completely absurd to make eggs glow in the dark.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Gab vorher kein Firefox Maskottchen. Es gibt mehr oder weniger noch ein Mozilla Maskottchen mit dem ursprünglichen Dino-Logo, falls du das im Kopf hast: